
Struccle(ストラクル) とは?
日本国産の Web スクレイピングツールです。
(参考:スクレイピングとは?)
ツールの動作環境はローカル(デスクトップアプリ)ではなく、クラウド上になります。
Web ページ上に公開されているデータを早く・簡単に・たくさん取得したい、という目的に適したツールです。
無料で広範囲の機能が使えて、CSV データでダウンロードすることで様々な用途に流用することができます。
さて、使い始める前に Struccle を使う上で知っておいてほしいスクレイピングや Struccle の構造・仕組み・特徴などを簡単に説明いたします。
これを理解した上で Struccle をお使いいただければ、よりツールに早く慣れ、使いこなすことができるでしょう。
スクレイピングについて
スクレイピングは、主に Python というプログラミング言語を使って行われることが多いです。
スクレイピングの基本的な仕組み
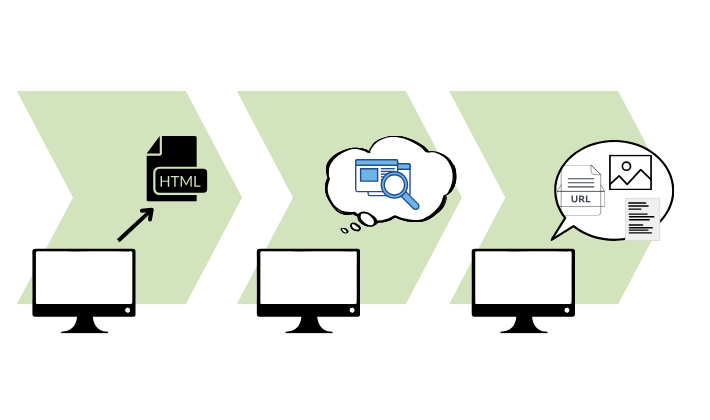
スクレイピングは、主に以下の3つのステップで成り立っています。
- Web ページの取得(リクエスト)
- 目的の Web サイトにアクセスし、そのページの HTML データを取得します。これは、Web ブラウザがサーバーに「このページを見せてください」とお願いするのと同じ動作です。
- 目的の Web サイトにアクセスし、そのページの HTML データを取得します。これは、Web ブラウザがサーバーに「このページを見せてください」とお願いするのと同じ動作です。
- HTML の解析(パーシング)
- 取得した HTML は、文字列の塊です。この文字列をコンピュータが理解しやすいように、タグ構造に基づいて解析(分解)します。
- 取得した HTML は、文字列の塊です。この文字列をコンピュータが理解しやすいように、タグ構造に基づいて解析(分解)します。
- データの抽出・整形
- 解析された HTML の中から、必要な情報(テキスト、画像、リンクなど)を特定し、取り出します。抽出したデータは、用途に合わせて不要な部分を削除したり、形式を変換したりする整形処理が行われます。
Struccle について
使い方は大きく分けて 2 種類あり、「テンプレート」機能を使うか否かです。
テンプレートを取得すると待っているだけで自動的に、対象サイトのデータが随時取得できます。
テンプレートに欲しいサイトがない場合などは、Struccle 内のチャットやお問い合わせからテンプレート作成依頼をするか、テンプレート機能を使わずご自身で取得設定を行います。
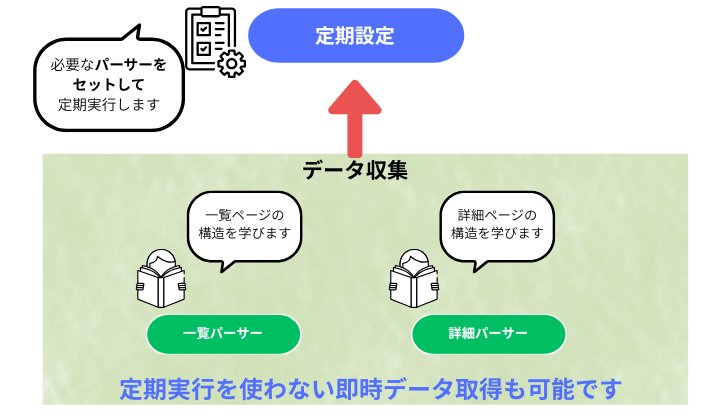
テンプレートを使わない場合の基本構造は「データ収集」と「定期設定」の 2 つのメニューから成ります。
データ収集では「パーサー」と呼ばれるデータ取得のための型(本来プログラミングで作る)を作り、定期設定ではタスクにパーサーをセットしデータ取得スケジュールを設定することで自動で定期的にデータ取得を実行することができます。
もちろん、スポット(一回きり)のデータ取得も可能です。
Struccle の構造
テンプレートを利用しない場合は以下の図のように、「データ収集」でパーサーを作成し、「定期設定」でセットしてスケジュールタスク(データ収集)を実行するのが基本の使い方となります。
パーサーの作成は対象サイトページの構造を学んでデータ収集の型を作るための工程です。
作ったパーサーは、対象サイトのデータ取得テンプレートのようなものとして機能します。
ページの構成の種類は大きく分けて 2 つ、一覧パーサー、詳細パーサーに分けられます。
また、一覧ページの URL が多く一覧パーサーでは対応しきれない場合、ページネーションパーサーを作成して対応する場合があります。
(一つのサイトに対して基本は、一覧パーサーと詳細パーサーの 2 種類を用意し、必要な場合はページネーションパーサーも作成します。)
こういった特徴を念頭に置いていただくと、より円滑にデータ取得ができるようになるでしょう。
さあ、次はスタートガイドを見てみましょう!>>0.Struccleの基本機能