今回はホットペッパービューティーの店舗情報を、「詳細ページパーサー」と「一覧ページパーサー」を用いることでより多く取得する方法をお伝えします。
初心者の方でもかんたんに使える、スクレイピングテンプレートも用意しております。
\ 無料でオーダーも可能 /
▼ 動画解説(※ 音声は出ません)
作業概要
今回のゴールは店舗検索結果 1 ページ目に表示された「池袋・目白のヘアサロン店舗情報を取得」とします。
そのため今回は、「大枠の情報 → 詳細の情報」という流れでデータを取得するような構成でスクレイピングが実行されるようにします。
言い換えると、「対象ページ全体の情報 → 個々の詳細ページの情報」という流れになります。
その準備に必要なものは、この 2 つです。
・一覧ページパーサー(一覧ページ URL)
・詳細ページパーサー(詳細ページ URL)
Extractor で「一覧ページパーサー」と「詳細ページパーサー」の 2 種類のパーサーを作り、それらを使って Schedule でタスク作成をしてスクレイピングを行います。
作業全体の流れ
① 一覧ページパーサー作成
② 詳細ページパーサーの作成
③ Scheduler でタスク作成(一覧・詳細パーサーを紐付ける)
④ 作成データの取得
対象サイトページ URL の取得
対象サイト:ホットペッパービューティー
店舗絞り込み条件:関東 > 池袋・目白 > 池袋・目白すべて
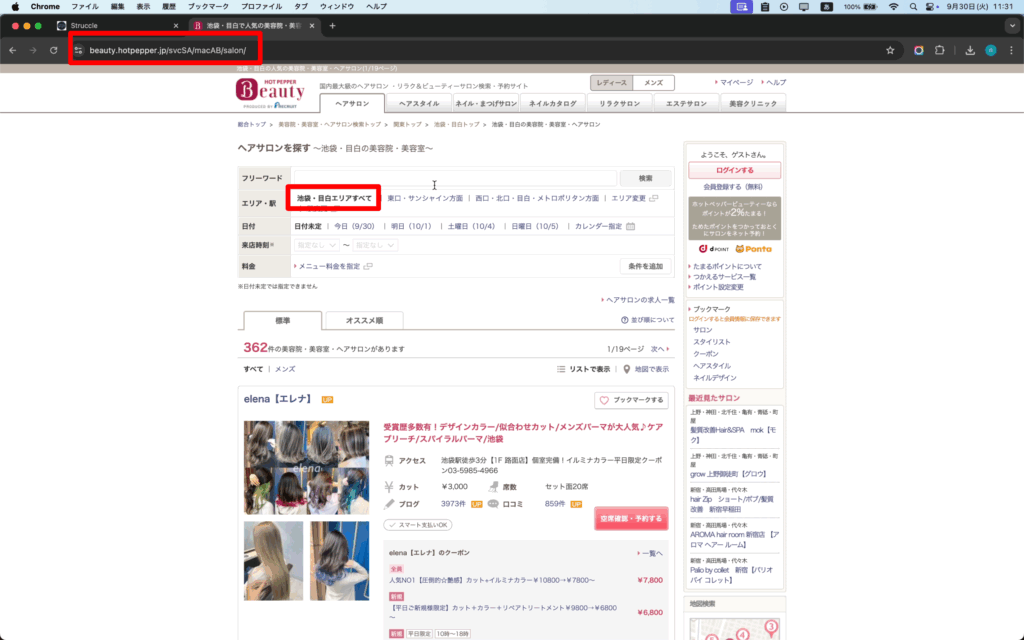
今回の対象ページ URL:
▼ この画面(一覧ページ)の URL を「一覧ページ URL」として取得
① 一覧ページパーサー作成
一覧ページパーサーを作成します。
・「Extractor」メニュー > 「NEW CHAT」でパーサーを新規作成
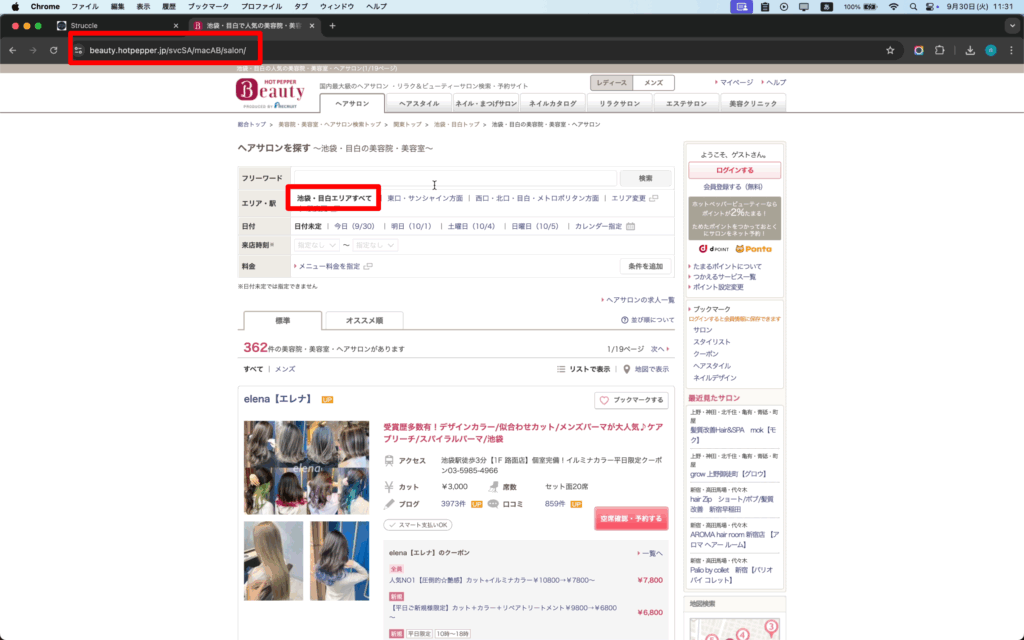
・一覧ページ(店舗一覧が表示されているページ)の URL を取得
画面例の URL:
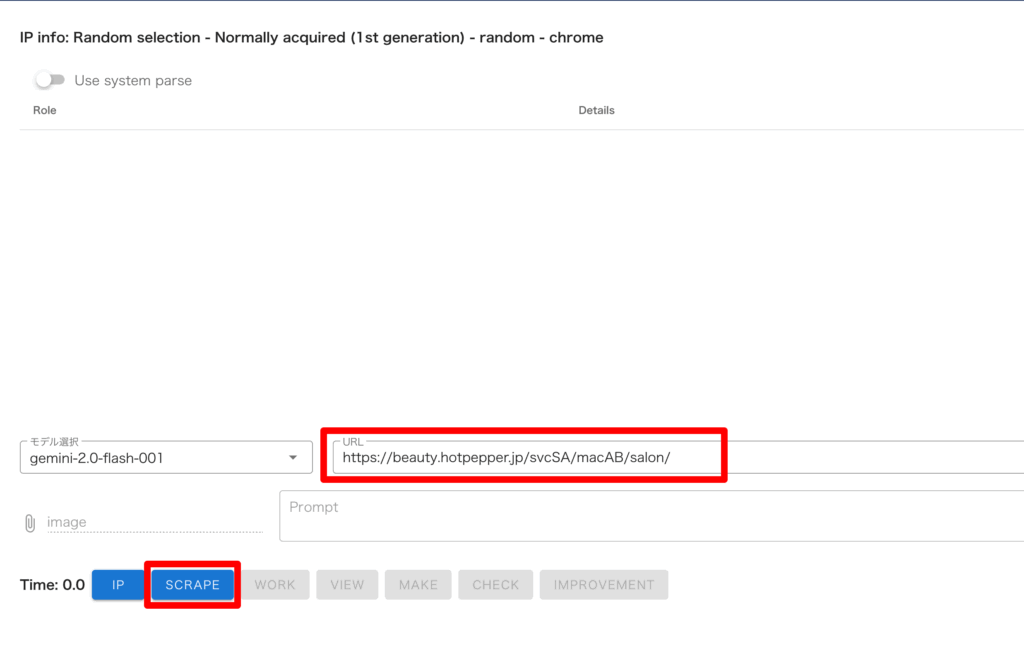
・取得した URL を「URL」に入力して「SCRAPE」を押し、「HIGH SPEED」モードを選択
HIGH SPEED は検索結果画面など、一覧データの取得などに適しています。

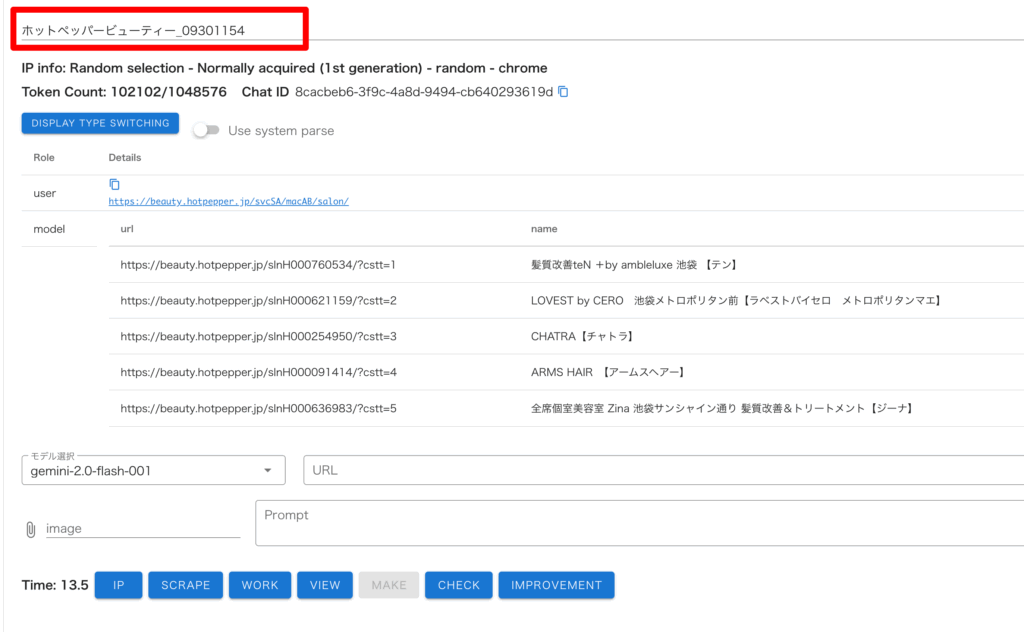
・「MAKE」を押してデータを作成
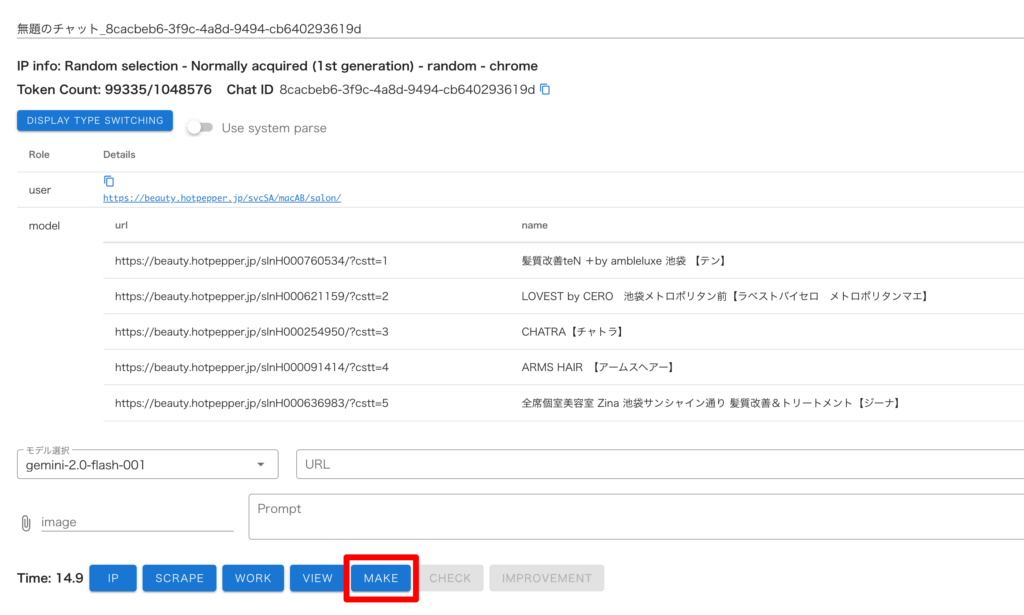
・「CHECK」を押して、作成したデータを確認
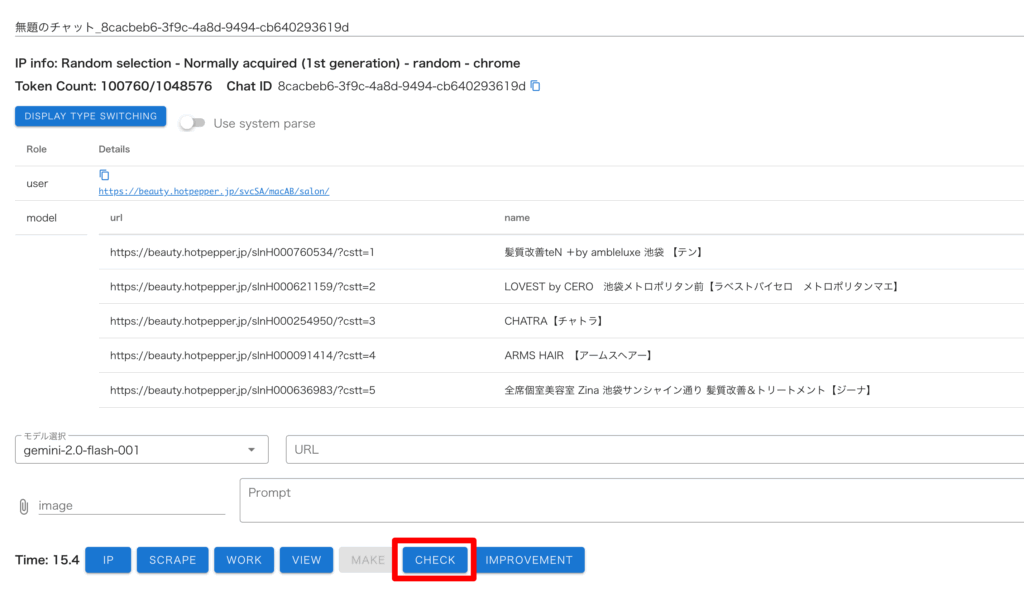
データは綺麗に取得できていますね。デフォルトでは取得件数は 5 件のみとなっています。
今回の対象ページでは 1 ページに 21 件の対象データありますので、21 件分取得できるように調整します。
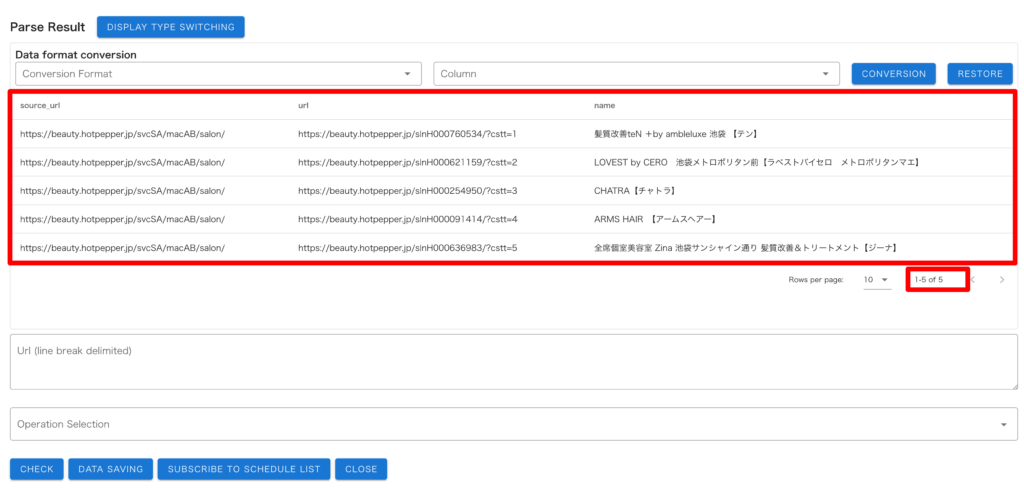
・「Prompt」に修正したい内容を入力し、「SCRAPE」を押す
「Prompt」で AI に指示をすることによってスクレイピングモデルの修正をします。
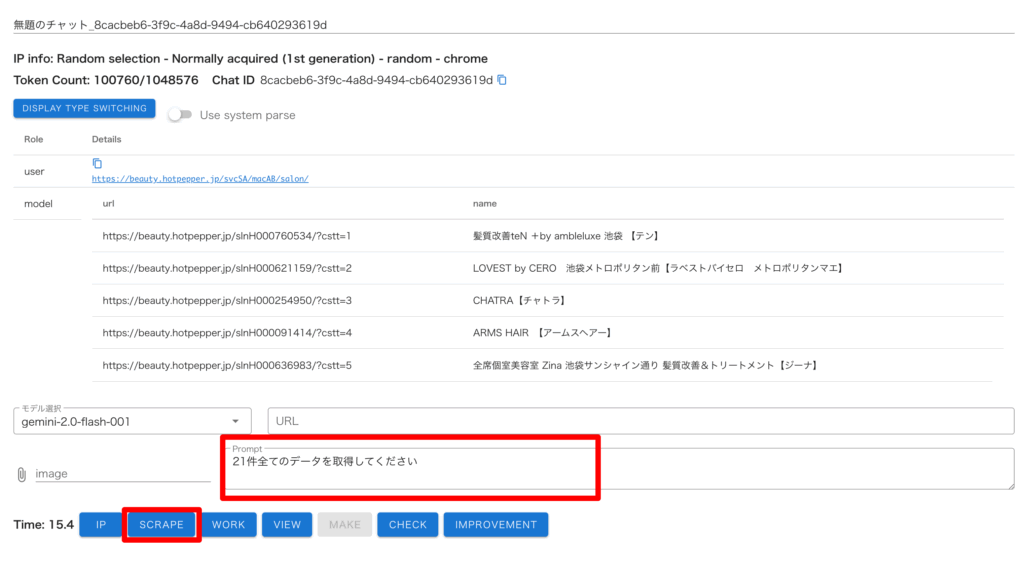
これでデータが全件(21件)取得されるように修正されました。
・「Url(line break delimited)」に一覧ページ URL を入力して「CHECK」を押すとデータ取得ができるので、別の一覧ページ URL を入力するなどしてパーサーの汎用性を確認
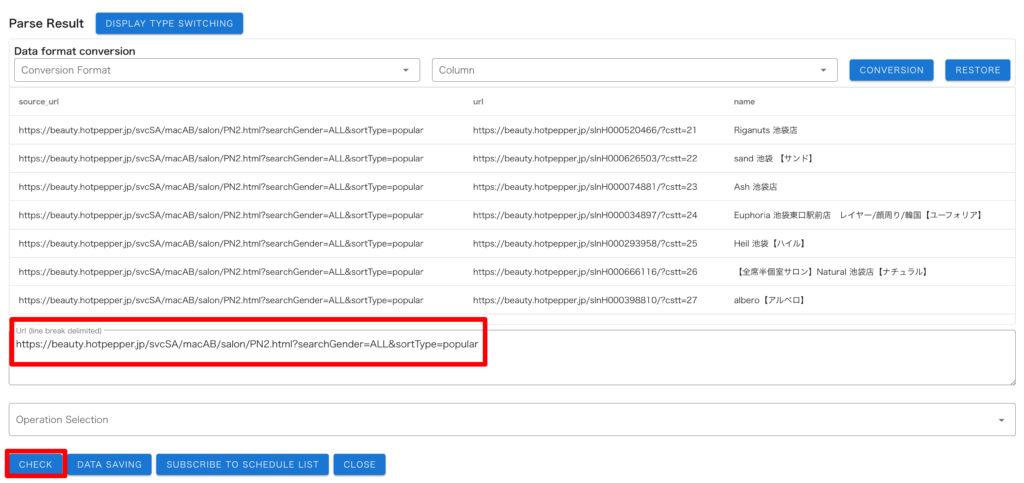
「CLOSE」でポップアップを閉じ、作成した一覧パーサーに名前をつけておきましょう。
これで一覧ページパーサーは完成です。
② 詳細ページパーサーの作成
詳細ページパーサーを作成します。
・「Extractor」メニュー > 「NEW CHAT」でパーサーを新規作成
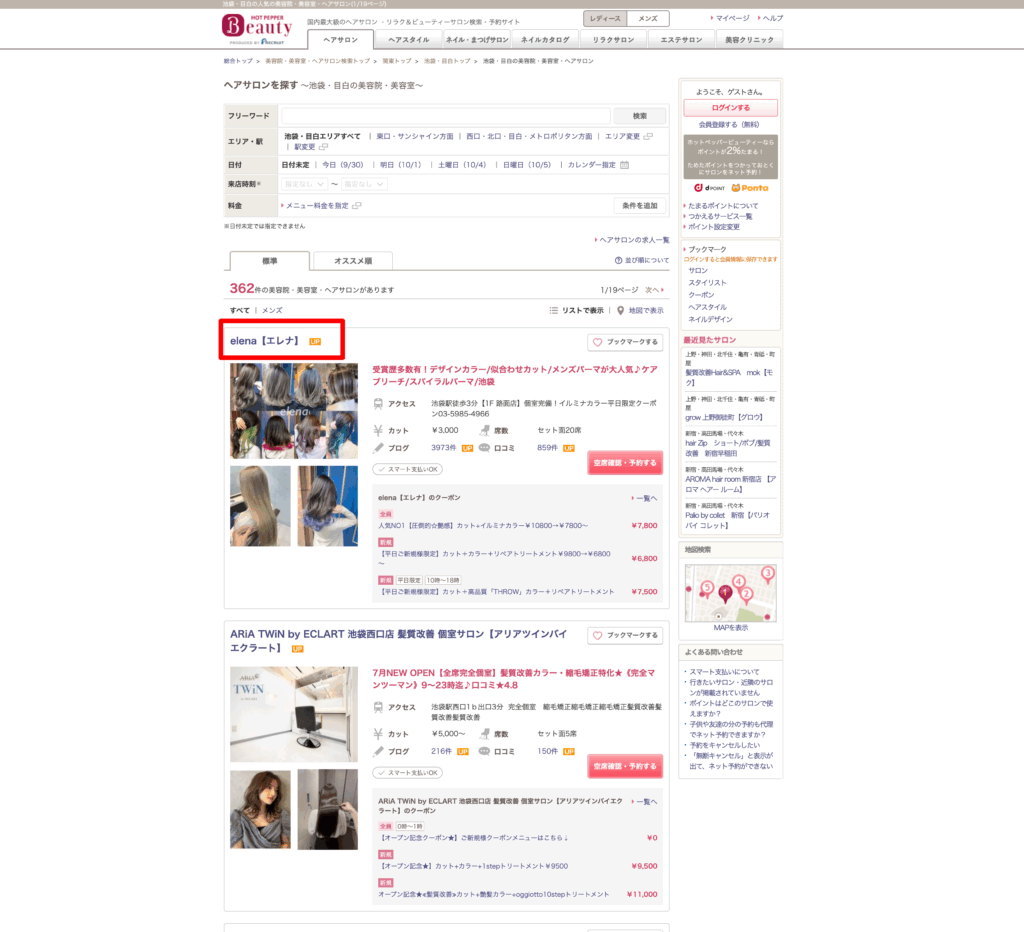
先ほどの一覧ページで、店舗名をクリックして表示される各店舗の詳細なページが「詳細ページ」です。
・詳細ページ(店舗詳細情報のページ)の URL を取得
画面例の URL:
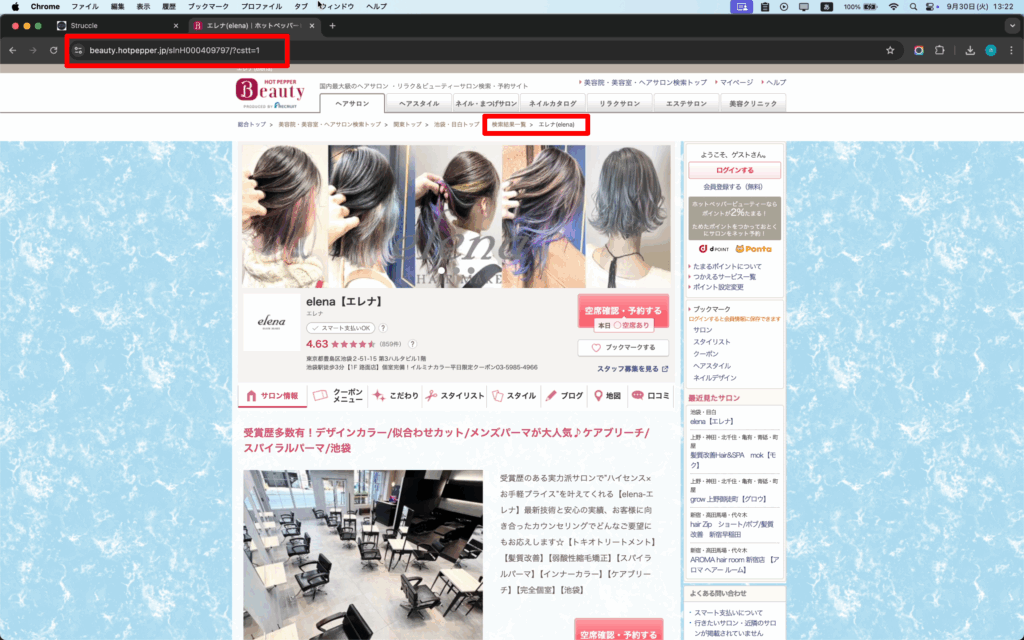
・取得した URL を「URL」に入力して「SCRAPE」を押し、「NORMAL」モードを選択
NORMAL は各店舗の詳細画面など、1 ページあたりに項目数の多いデータの取得などに適しています。

・「MAKE」を押して、データを作成
・「CHECK」を押して、作成したデータを確認
・「Url(line break delimited)」に詳細ページ URL を入力して「CHECK」を押すとデータ取得ができるので、別の詳細ページ URL を入力するなどしてパーサーの汎用性を確認
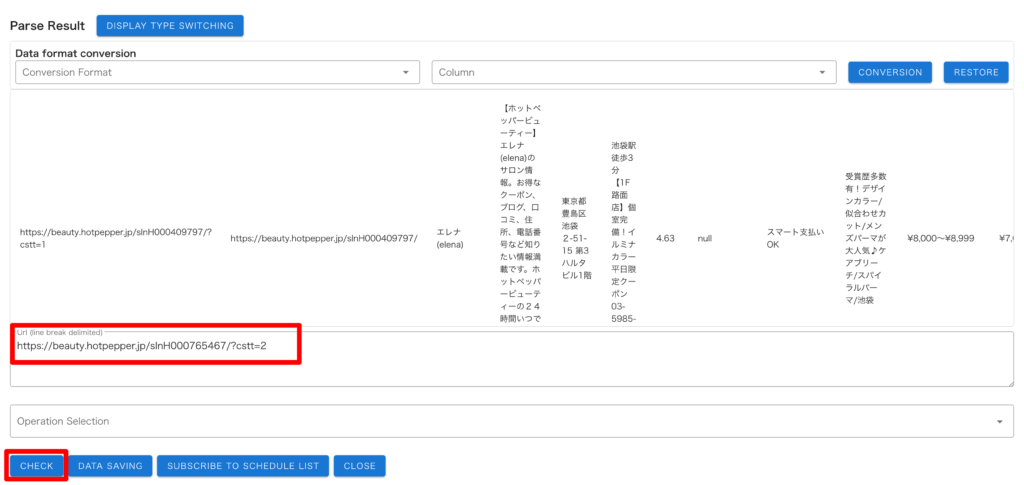
「CLOSE」でポップアップを閉じ、作成した一覧パーサーに名前をつけておきましょう。
これで詳細ページパーサーは完成です。
取得できていない項目を取得する
「CHECK」で確認したときに自動取得出来ていない項目もあると思います。
その際に項目を追加で取得する方法を 2 パターン紹介いたします。
①「VIEW」機能を利用して取得する
・パーサー作成画面で「VIEW」を押す
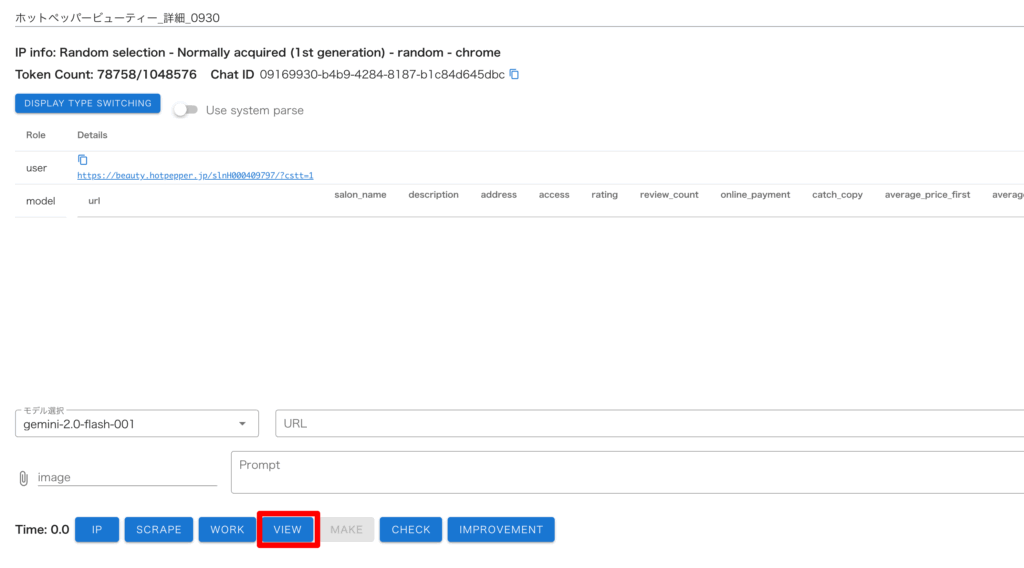
・画面左に取得対象のページが表示されるので、「Page Selection」でこのページを選択して、取得したいデータ項目を直接クリック
・「Column Name」に取得するデータの項目名を入力し、「EXTRACT」を押す
・完了したら、「CHECK」で今回取得したデータを確認
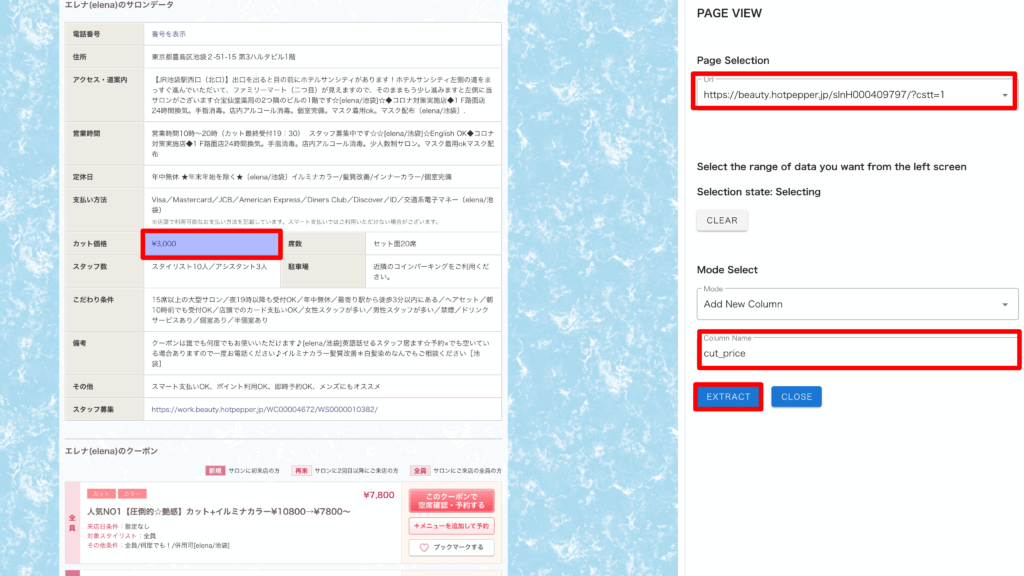
項目が追加できていれば OK です。
②「Prompt」を利用して取得する
Prompt を利用して追加取得する方法もあります。
今回は「電話番号」項目を追加取得してみます。
・「Prompt」に指示を入力し、「SCRAPE」を押す
・「CHECK」画面を開き、詳細ページ URLを入力&「CHECK」して、「電話番号」データが取得できているか確認
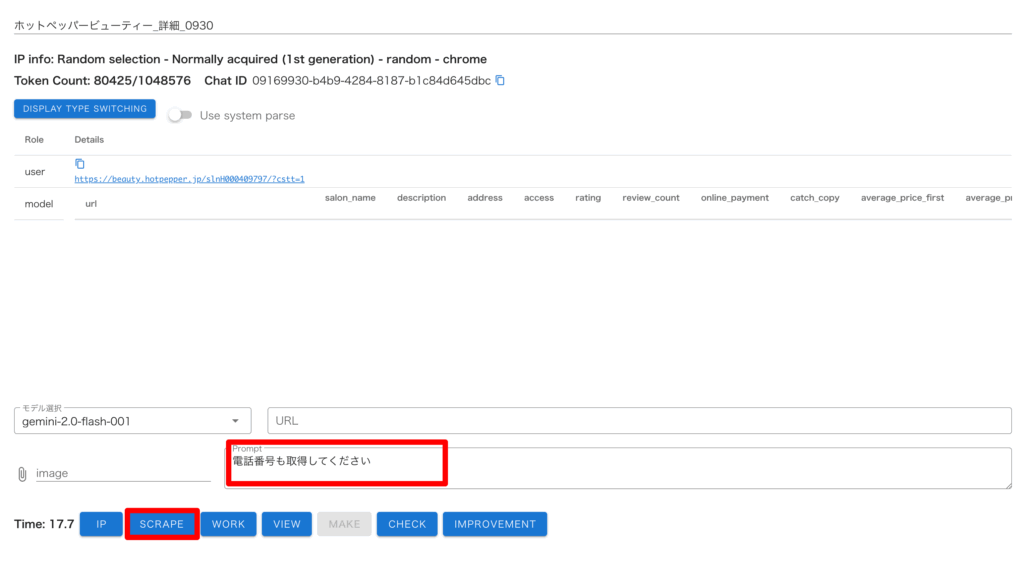
これで取得できていなかった電話番号のデータを取得することができました。
今回の事例以外にも Prompt に修正したい内容を入力すれば、AI がそれに従ってスクレイピングモデルを修正してくれるので、様々な指示を試してもらえればと思います。
③ Scheduler でタスク作成(一覧・詳細パーサーを紐付ける)
ここまで作成した一覧ページパーサーと詳細ページパーサーを紐付けて、データ取得(スクレイピング)をするための Scheduler タスク作成をします。
1.タスク作成方法
・「Scheduler」メニューの「Add Schedule」で新しいタスクを作成
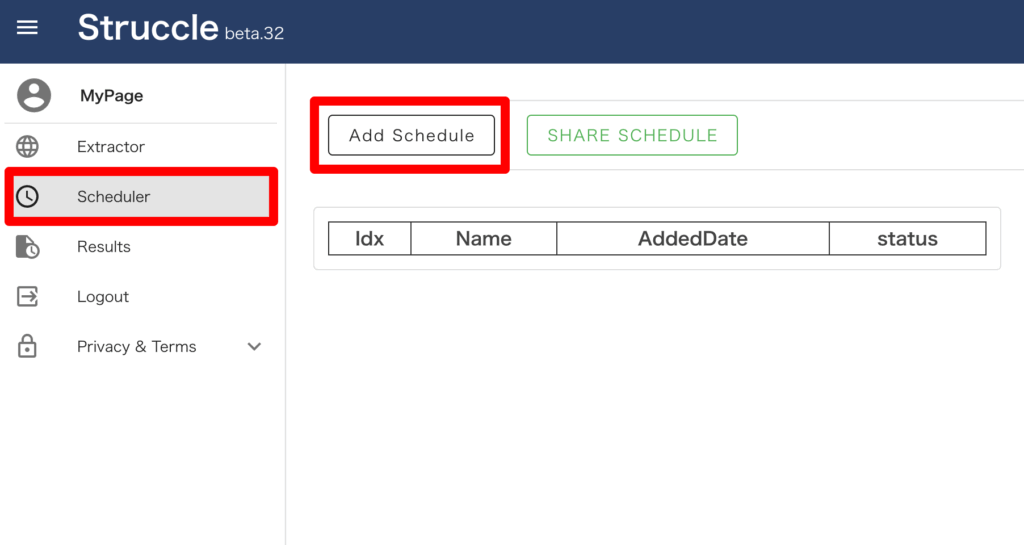
「Add Schedule」画面でパーサーのセットやタスクの詳細設定をします。
▼ 設定内容表
| 機能名 | 設定内容 |
| scd_name * | タスクの名称(任意) |
| Memo | メモ |
| Schedule | 実行日時の設定(何かしら日付をご選択ください) |
| Select URL * | 対象 URL |
| Select Parser * | パーサー(上流工程)。今回は一覧パーサーをセット |
| Select Column * | url(詳細パーサーとの接続キーとなる) |
| Select Work * | 設定不要 |
| Next Select Parser | パーサー(配下)詳細パーサーをセット |
| 設定不要 | |
| source_url(さらに配下のパーサーとの接続キーとなるが、今回はないのでなんでもOK) |
▼ 設定画面例
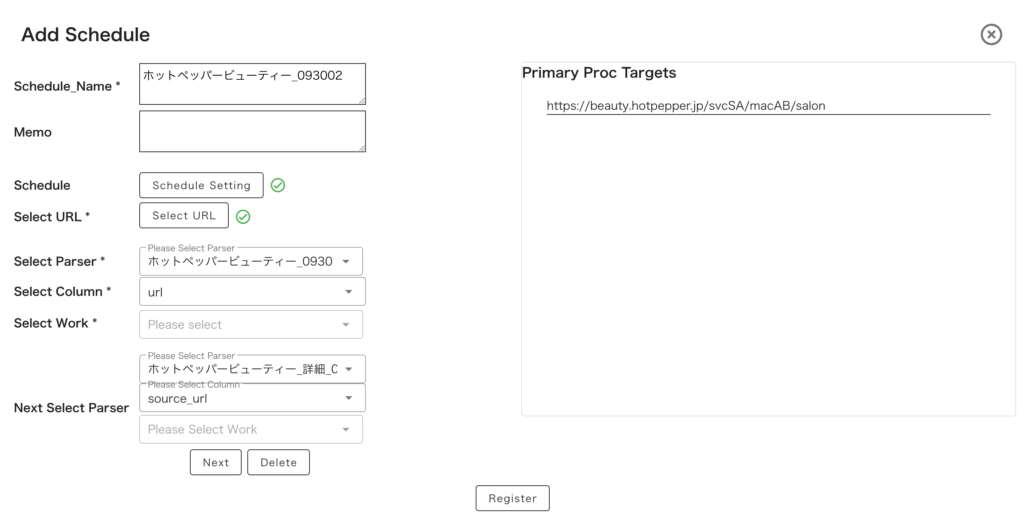
・「Select URL *」にはスクレイピング対象 URL(一覧ページ URL)を入力して Add を押して追加
今回の一覧ページ URL 例:
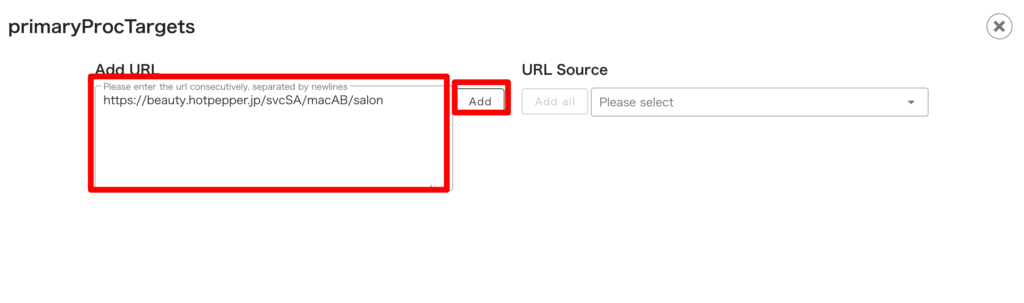
「Select Parser *」には先ほど作成した詳細ページパーサーをセットし、
「Select Column *」には一覧ページパーサー作成時のカラムを選択します。
これは配下のパーサーと接続するキーとなります(今回は url)。
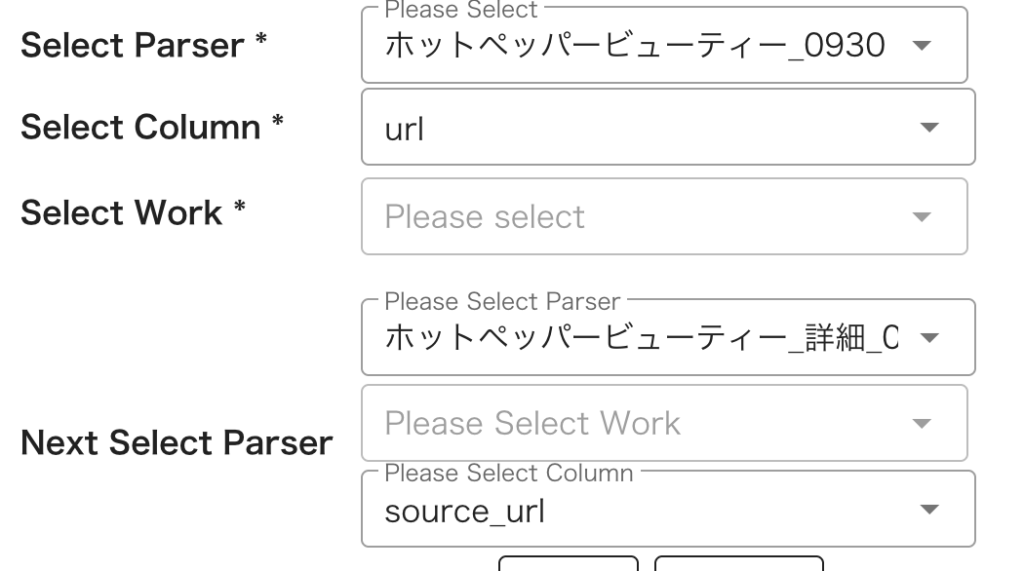
同じような感じで、今度は一覧パーサーの配下にくる詳細パーサーの設定をします。
「Next Select Parser」上段には詳細パーサーをセットし、下段はどのカラムでもOKです。
・設定が終わったら「Register」で登録
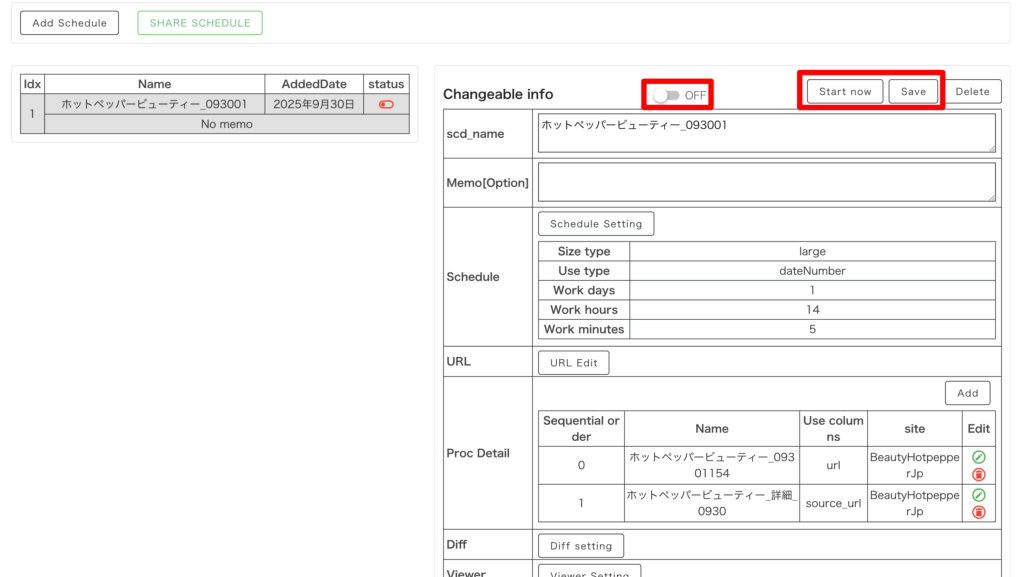
・作成したタスクを押して設定詳細画面(Changeable info)を開く
・上部にある ON・OFF のトグルで定期取得のアクティベートを切り替え
※ 一回単発の取得であれば OFF に
※ 自動定期取得を実行したい場合は ON に
設定変更をした場合は忘れずに「Save」をしましょう。
今回は今すぐデータ収集を開始するので「Start Now」を押してください。
Scheduler でのタスク作成・実行が完了しました。
これでスクレイピングが開始されました。
④ 作成データの取得
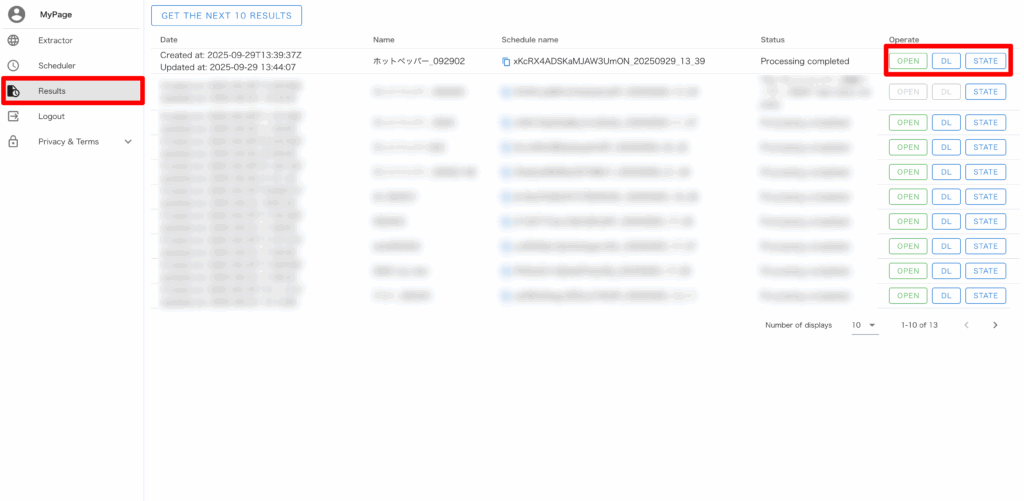
「Result」メニューから Scheduler タスクの実行状況確認や、完了した収集データをダウンロードできます。
Status:ここの項目に「Processing completed」の表示が出たらデータ収集完了です。
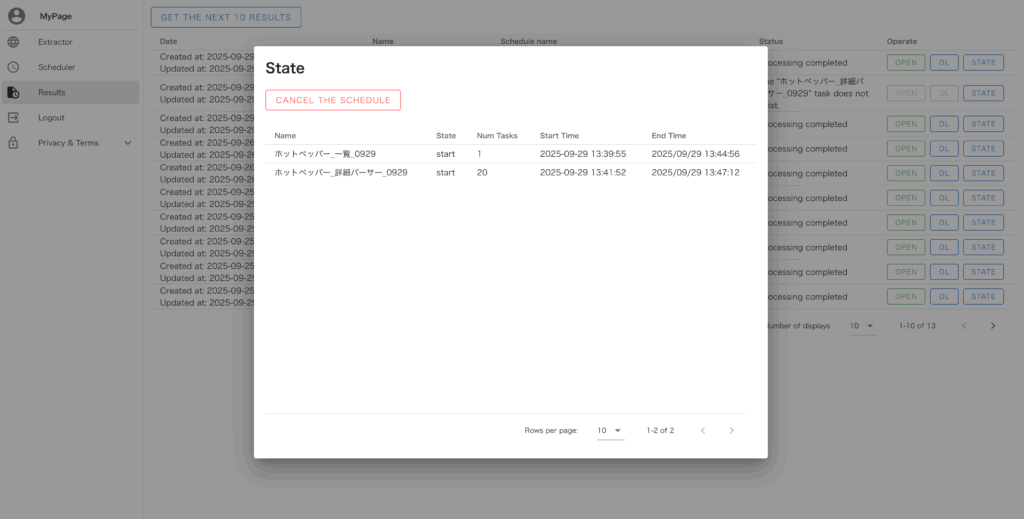
STATE:パーサーの処理状況や実行終了予定時刻の確認ができます。
OPEN:完了後、取得したデータを確認できます
DL:CSV データをダウンロードできます
ダウンロードをすれば下記のような CSV データが取得できます。
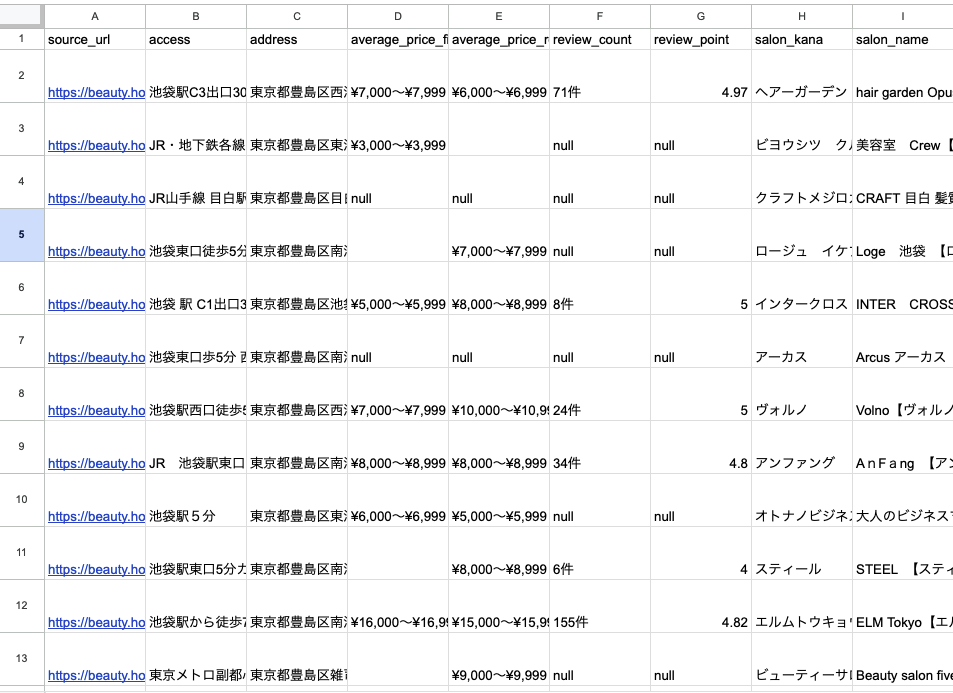
今回の CSV データ取得例は以下、データサンプルのスプレッドシートにて公開中です。
>>データサンプルはこちら<<
お疲れ様でした。以上が大量データを取得する方法です。
「検索結果のデータを全件取得したい」「定期的に自動取得したい」などもっと使いこなしたい方は、ぜひ操作ガイドや FAQ を参考に Struccle を使ってみてください。
お問い合わせやご質問も、Struccle 内のチャットフォームなどからお気軽にどうぞ。