
入門ガイド
データ収集の全体像
ここからは、Struccle(ストラクル)の利用開始から最初のデータ抽出までの操作を最短ステップでご案内します。
▼ 動画解説(34秒 ※音声は出ません)
利用前の準備
1) アカウント登録
以下から無料アカウントを作成します。
2) 情報入力
登録メールアドレスと任意のパスワードを入力
▼
「SIGN UP」を押す
▼
登録確認メールが届くので、メール内の URL を押して登録完了
※迷惑メールフォルダに振り分けられている場合がございますので、ご注意ください。
データ収集の流れ(最短)
「パーサー作成 > URL 準備 > Scheduler タスク作成 > 収集開始 > データ編集・出力」の 5 ステップでデータ収集を行います。
1. パーサー作成
Extractor を開き、取得したいページの URL・データ項目を設定していきます。基本は取得項目を AI が自動で設定してくれます。必要に応じて欲しい項目を追加指定します。
2. URL 準備
取得したいサイトページの URL を準備します。
3. Scheduler タスク作成
Extractor で作成したパーサーを使い、URL や実行日時を設定する機能(Scheduler)で各項目を設定します。
4. 収集開始
Scheduler で設定した内容に問題がなければスクレイピングを開始。
開始後はスクレイピング終了予定時間も確認できます。
(指定時間ではなくすぐに開始することもできます)
5. データ編集・出力
スクレイピングが完了すれば Results から下記のように CSV データをダウンロードできるようになります。
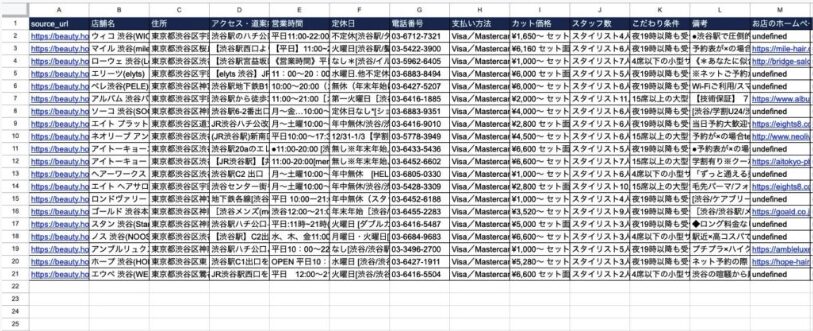
Excel や Google スプレットシートなどでももちろん編集等できますので、自由にデータをご活用ください。
ページの構造について
ここからは、データ取得に使うパーサー作成をするにあたって関連する知識である、ページ構造の特徴「一覧ページ」と「詳細ページ」について解説していきます。
これを理解することによって、より作業効率が上がります。
一覧ページ
下記のように、店情報が一覧で掲載されているページを「一覧ページ」と言います。
詳細ページの入り口となる URL が複数並んで表示されていることが特徴です。
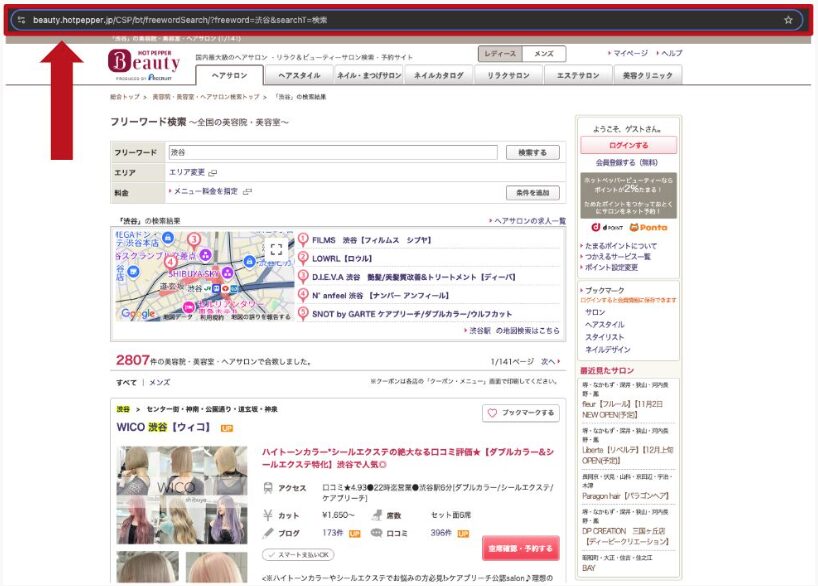
一覧ページの URL は上記の赤矢印の箇所から取得し、Extractor のパーサーや Scheduler で取得したいページを設定する際などに使用します。
詳細ページより簡易な情報、例えば店舗名やアクセスなどのデータはここで取得できます。
また、Scheduler のタスクで「一覧ページ」と「詳細ページ」のパーサーをリンクさせてセットすることで、大量のデータを一気に取得することが可能です。
詳細ページ
下記のように、店舗の一覧ページから店の詳細ページに入ったページを「詳細ページ」と言います。
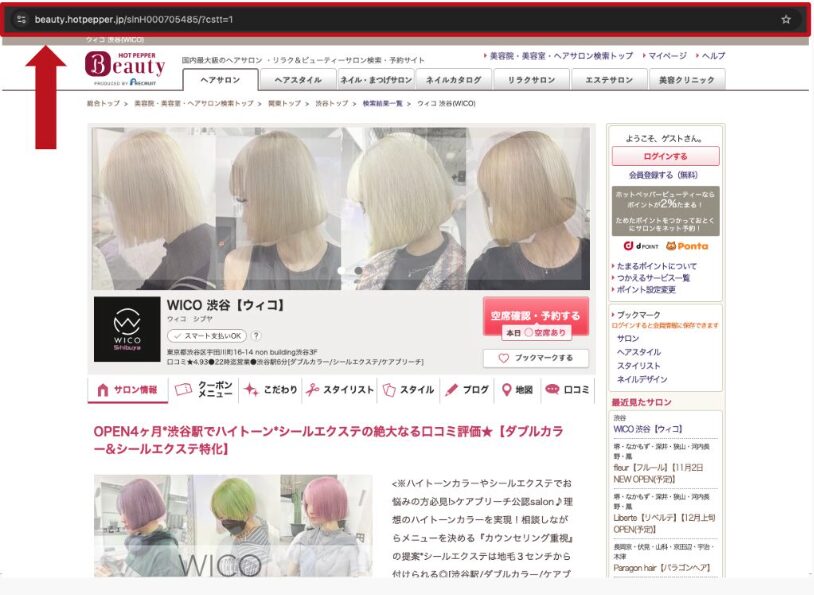
このページを取得対象としたい場合は、上記の赤四角の箇所の「URL」を取得すれば、店の詳細情報を取得することができます。
例えば、一覧ページより詳細な店舗の情報を取得したい場合は、詳細ページから情報を取得します。
それでは次にSTEP.2の
を学んでいきましょう!