
入門ガイド
Scheduler で自動定期取得タスクを設定する
このガイドでは、これまで作成してきたパーサーを使って Scheduler でタスクを作成し、それを使うことによって自動でのデータ定期取得を設定します。
▼ 動画解説_詳細ページ(44秒 ※音声は出ません)
▼ 動画解説_一覧 → 詳細(49秒 ※音声は出ません)
操作方法
「詳細ページ」のみ取得したい場合
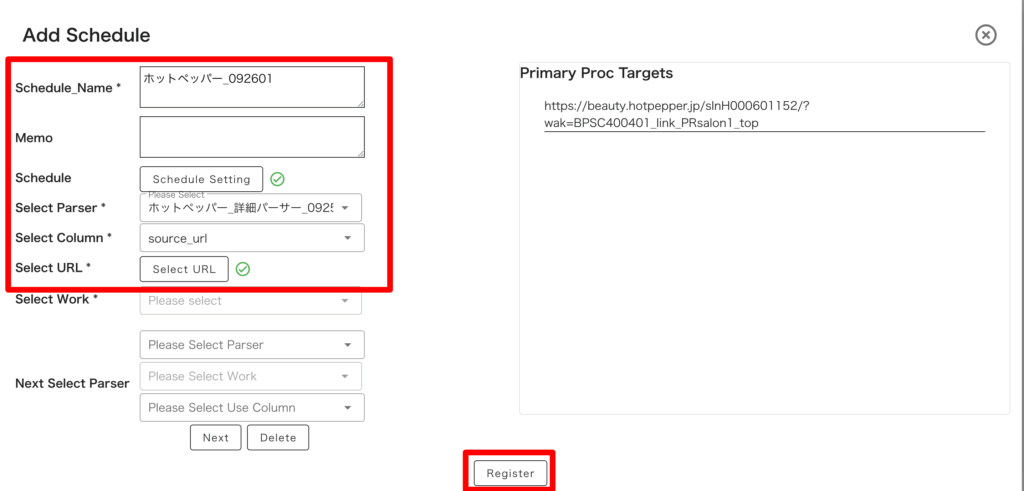
Scheduler から「Add Schedule」を押してタスクを新規作成します。
先ほど作成したパーサーをセットし、タスク動作に関する設定をしていきます。
詳細は以下の表を参考にしてください。
パーサーをセットするときは、必ず使うパーサーのうち上流工程のものからセットしていってください。
例えば一覧パーサー、詳細パーサーの 2 つを使う場合、「大枠 → 詳細」の流れでセットする必要があるので、一番最初にセットすべきパーサーは一覧パーサーです。
ここでは詳細ページのみ取得したい場合なので、「詳細ページ」パーサーのみを使います。
| 機能名 | 設定内容 |
| scd_name * | タスクの任意の名称 |
| Memo | メモ |
| Schedule | 実行日時の設定。何かしら日付をご選択ください |
| Select Parser * | パーサー(上流工程)。今回は詳細パーサーをセット |
| Select Column * | source_url |
| Select URL * | 対象 URL のセット |
| Next Select Parser | 今回は配下のパーサーがないので設定不要 |
↓ 上の表に倣い適宜設定が終わったら、「Register」を押して登録。
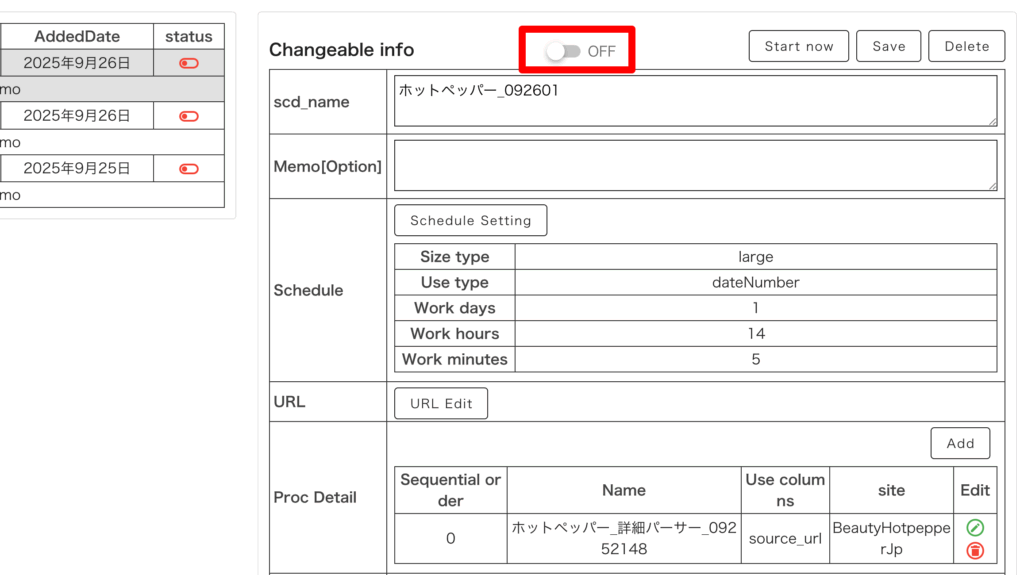
登録後、一覧からタスクを選択すると詳細画面が開くので、毎回定期取得したい場合(Scheduleで定期取得を設定した場合)は赤枠内を ON に、そうでない場合は OFF にしておきましょう。
そして設定を変更したら「Save」を押して保存してください。
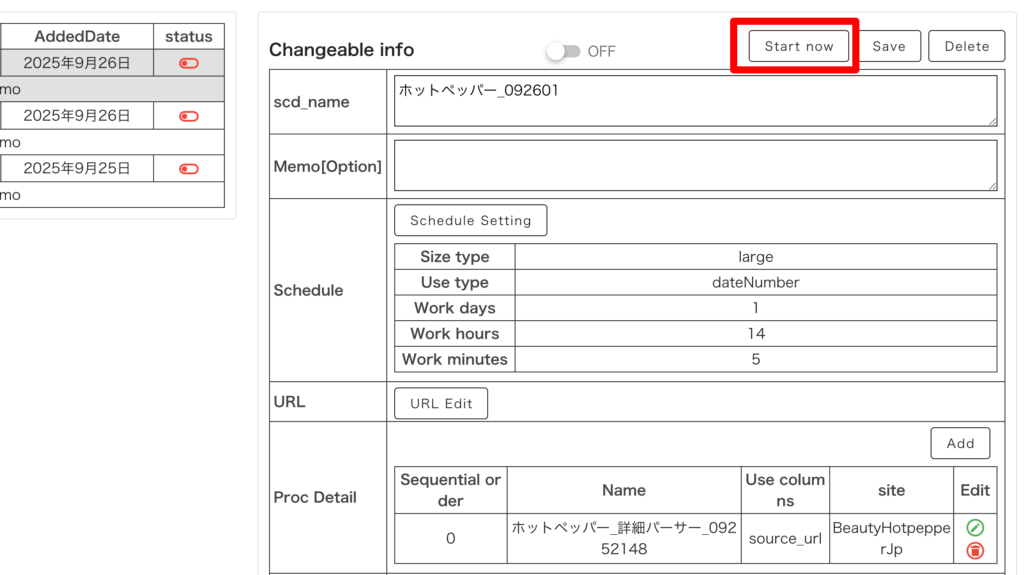
今すぐスクレイピングを開始したい場合は、「Start Now」を押してください。
一覧ページ→詳細ページを取得したい場合
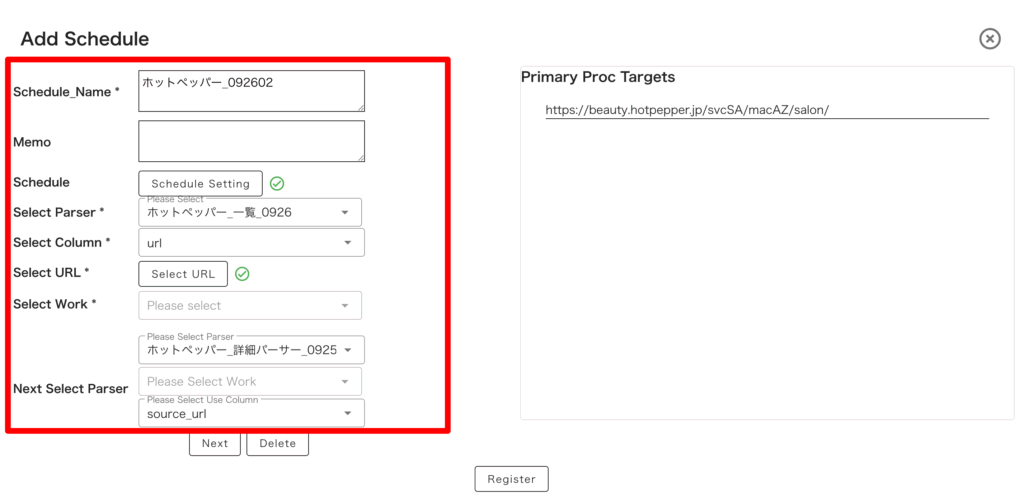
Scheduler から「Add Schedule」を押してタスクを新規作成します。
パーサーをセットする時は、必ず上流工程のものからでしたよね。
なので今回パーサーをセットする順番は、一覧ページパーサー → 詳細ページパーサーになるということに留意してください。
| 機能名 | 設定内容 |
| scd_name * | タスクの任意の名称 |
| Memo | メモ |
| Schedule | 実行日時の設定。何かしらご選択ください |
| Select Parser * | パーサー(上流工程)。今回は「一覧ページ」パーサーをセット |
| Select Column * | 続けてセットする配下のパーサーである「詳細ページ」パーサーと紐付ける項目を指定。 今回は「url」を選択 |
| Select URL * | 対象 URL のセット |
| Next Select Parser | パーサー(配下)。今回は「詳細ページ」パーサーをセット |
| 設定不要 | |
| 上流パーサーと紐づける項目を指定。 今回は「source_url」を選択 |
↓ 上の表に倣い適宜設定が終わったら、「Register」を押して登録。
登録後、一覧からタスクを選択すると詳細画面が開くので、毎回定期取得したい場合(タスク設定した日時に実行したい場合)は赤枠内を ON に、そうでない場合は OFF にしておきましょう。
そして設定を変更したら「Save」を押して保存してください。
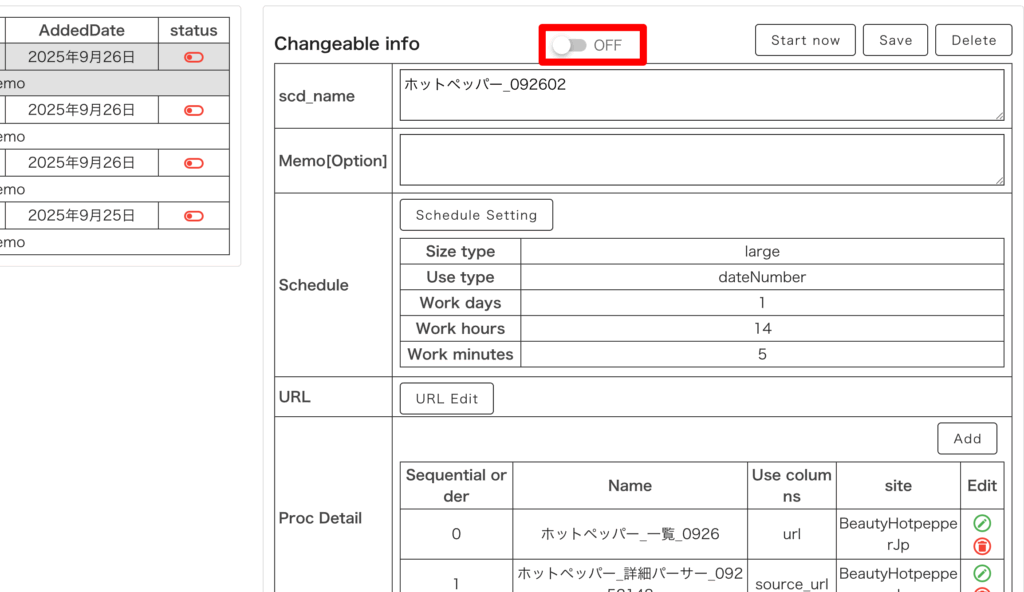
今すぐスクレイピングを開始したい場合は、「Start Now」を押してください。
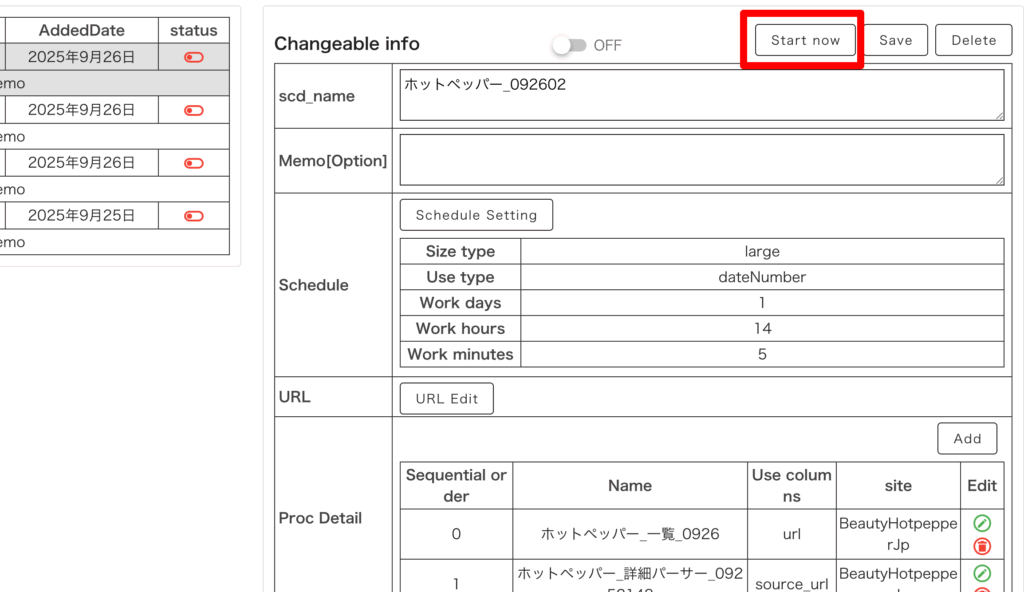
これでスケジューラーでデータ収集が開始されました。
それでは次にSTEP.4の
を学んでいきましょう!